
This post will cover some new dataset functionality I’ve recently added to Incanter, including the use of MongoDB as a back-end data store for datasets.
Basic dataset functionality
First, load the basic Incanter libraries
(use '(incanter core stats charts io))
Next load some CSV data using the incanter.io/read-dataset function, which takes a string representing either a filename or a URL to the data.
(def data
(read-dataset
"http://github.com/liebke/incanter/raw/master/data/cars.csv"
:header true))
The default delimiter is \, but a different one can be specified with the :delim option (e.g. \tab). The cars.csv file is a small sample data set that is included in the Incanter distribution, and therefore could have been loaded using get-dataset,
(incanter.datasets/get-dataset :cars)
See the documentation for get-dataset for more information on the included sample data.
We can get some information on the dataset, like the number of rows and columns using either the dim function or the nrow and ncol functions, and we can view the columns names with the col-names function.
user> (dim data) [50 2] user> (col-names data) ["speed" "dist"]
We can see that there are just 50 rows and two columns and that the column names are “speed” and “dist”. The data are 50 observations, from the 1920s, of automobile breaking distances observed at different speeds.
I will use Incanter’s new with-data macro and $ column-selector function to access the dataset’s columns. Within the body of a with-data expression, columns of the bound dataset can be accessed by name or index, using the $ function, for instance ($ :colname) or ($ 0).
For example, the following code will create a scatter plot of the data (speed vs. dist), and then add a regression line using the fitted values returned from the incanter.stats/linear-model function.
(with-data data
(def lm (linear-model ($ :dist) ($ :speed)))
(doto (scatter-plot ($ :speed) ($ :dist))
(add-lines ($ :speed) (:fitted lm))
view))
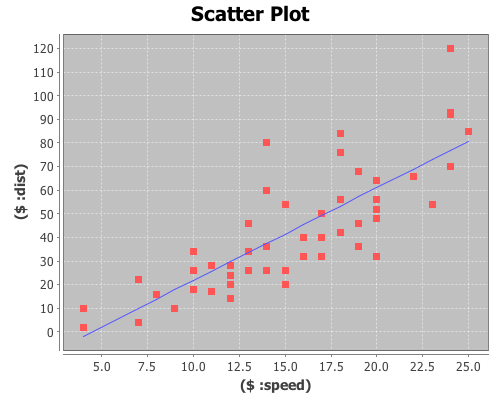
Within the with-data expression, the dataset itself is bound to $data, which can be useful if you want to perform operations on it. For instance, the following code uses the conj-cols function to prepend an integer ID column to the dataset, and then displays it in a window.
(with-data (get-dataset :cars) (view (conj-cols (range (nrow $data)) $data)))
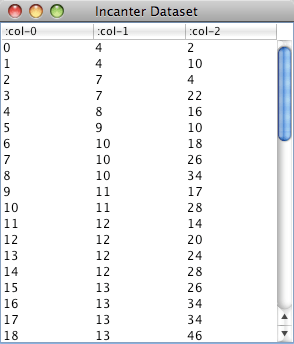
The conj-cols function returns a dataset by conjoining sequences together as the columns of the dataset, or by prepending/appending columns to an existing dataset, and the related conj-rows function conjoins rows.
We can create a new dataset that adds the fitted (or predicted values) to the original data using the conj-cols function.
(def results (conj-cols data (:fitted lm)))
You’ll notice that the column names are changed to generic ones (i.e. col-0, col-1, col-2), this is done to prevent naming conflicts when merging datasets. We can add more meaningful names with the col-names function.
(def results (col-names data [:speed :dist :predicted-dist]))
We could have used the -> (thread) macro to perform both steps, as well as add the residuals from the output of linear-model to the dataset
(def results (-> (conj-cols data (:fitted lm) (:residuals lm))
(col-names [:speed :dist :predicted :residuals])))
Querying data sets with the $where function
Another new function, $where, lets you query an Incanter dataset using a syntax based on MongoDB and Somnium’s Congomongo Clojure library.
To perform a query, pass a query-map to the $where function. For instance, to get the rows from the results data set where the value of speed is 10, use
($where {:speed 10} results)
For the rows where the speed is between 10 and 20, use
($where {:speed {:$gt 10 :$lt 20}} results)
For rows where the speed is in the set #{4 7 24 25}, use
($where {:speed {:$in #{4 7 24 25}}} results)
Or not in that set,
($where {:speed {:$nin #{4 7 24 25}}} results)
Like the $ function, $where can be used within with-data, where the dataset is passed implicitly. For example, to get the mean speed of the observations that have residuals between -10 and 10 from the results dataset,
(with-data results
(mean ($ :speed ($where {:residuals {:$gt -10 :$lt 10}}))))
which returns 14.32.
Query-maps don’t support ‘or’ directly, but we can use conj-rows to construct a dataset where speed is either less than 10 or greater than 20 as follows:
(with-data results
(conj-rows ($where {:speed {:$lt 10}})
($where {:speed {:$gt 20}})))
An alternative to conjoining query results is to pass $where a predicate function that accepts a map containing the key/value pairs of a row and returns a boolean indicating whether the row should be included. For example, to perform the above query we could have done this,
(with-data results ($where (fn [row] (or (< (:speed row) 10) (> (:speed row) 20)))))
Storing and Retrieving Incanter datasets in MongoDB
The new incanter.mongodb library can be used with Somnium’s Congomongo to store and retrieve datasets in a MongoDB database.
MongoDB is schema-less, document-oriented database that is well suited as a data store for Clojure data structures. Getting started with MongoDB is easy, just download and unpack it, and run the following commands (on Linux or Mac OS X),
$ mkdir -p /data/db $ ./mongodb/bin/mongod &
For more information, see the MongoDB quick start guide.
Once the database server is running, load Incanter’s MongoDB library and Congomongo,
(use 'somnium.congomongo) (use 'incanter.mongodb)
and use Congomongo’s mongo! function to connect to the “mydb” database on the server running on the localhost on the default port.
(mongo! :db "mydb")
If mydb doesn’t exist, it will be created. Now we can insert the results dataset into the database with the incanter.mongodb/insert-dataset function.
(insert-dataset :breaking-dists results)
The first argument, :breaking-dists, is the name the collection will have in the database. We can now retrieve the dataset with the incanter.mongodb/fetch-dataset function.
(def breaking-dists (fetch-dataset :breaking-dists))
Take a look at the column names of the retrieved dataset and you’ll notice that MongoDB added a couple, :_ns and :_id, in order to uniquely identify each row.
user> (col-names breaking-dists) [:speed :_ns :_id :predicted :residuals :dist]
The fetch-dataset function (and the congomongo.fetch function that it’s based on) support queries with the :where option. The following example retrieves only the rows from the :breaking-dists collection in the database where the :speed is between 10 and 20 mph, and then calculates the average breaking distance of the resulting observations.
(with-data (fetch-dataset :breaking-dists
:where {:speed {:$gt 10 :$lt 20}})
(mean ($ :dist)))
The syntax for Congomongo’s query-maps is nearly the same as that for the $where function, although :$in and :$nin take a Clojure vector instead of a Clojure set.
For more information on the available functionality in Somnium’s Congomongo, visit its Github repository or read the documentation for incanter.mongodb
(doc incanter.mongodb)
The complete code for this post can be found here.

Cool – sounds like the combination of Incanter with a persistent data store could be a winning combination. One of the things that I liked about R (not that I’ve used it much) was it’s ides of a persistent workspace.
One thing: the last $where example would probably be more readable if rewritten using the #() reader macro, like so:
(with-data results
($where #(or (< (:speed %) 10)
(> (:speed %) 20))))
I go back and forth on whether I think the #() notation is more or less readable. :-)
Can you explain why is MongoDB a good choice for incanter (as opposed to Clojure more generally?) Everything that I work with (in R) that is not rectangular, is indexed …
Do you mean as opposed to SQL databases, or other schema-less databases?
MongoDB can easily persist arbitrarily deeply nested Clojure data structures, which makes it a convenient choice, but that’s not to say there are not many other options, all equally useful.
Is there a jar on clojars that has this new code? I was using incanter “1.0-master-SNAPSHOT” in leiningen and it didn’t behave. I had to git pull the newest source and do a new mvn install to be able to play with the commands in this post.
I’m afraid not, the new code hasn’t be uploaded to Clojars yet. Hopefully soon.
I was able to get this working via Leiningen by:
1) pulling Incanter from github
2) mvn install the “working” branch
3) add incanter/incanter-app “1.0-master-SNAPSHOT” to my lein deps
4) run lein deps
I suppose YMMV. I just did it this way to get everything pulled via Lein.
Yep, the process Kyle used is what I recommend if you are building with Leiningen.
First install Incanter with Maven (mvn install), and then when you include an incanter module (e.g. incanter-app, incanter-core, incanter-charts, etc.) in your project.clj dependencies, it will pull it from your local repository.
Pingback: Closer To The Ideal » Blog Archive » Incanter: an R-like statistical package for the JVM
I want to read a data set from a textfile and then insert it into mongodb like you describe it in this post but it’s a big data set and I get a “out of memory” error.
I think I should insert the textfile directly into mongodb but I dont know how to do it, and I have doubts about using the fetch-dataset afterwards…
Can I save a textfile as a dataset in mongodb db and then fetch-dataset it? How can I do it?
Thanks
Hi Filipe,
If the data is too big to read in at once, either increase the amount of memory allocated to the JVM (see Incanter’s script/repl script for an example), or use the lazy io functions, from a library like clojure.contrib.duckstreams, to read in and then store the data as you go.
You can use congomongo directly to insert and read data from MongoDB, see the examples on its Github page http://github.com/somnium/congomongo.
Incanter’s insert-dataset function just stores the :rows entry of the dataset map. In other words it stores a vector of maps, where each map’s keywords correspond to the column names of the dataset.
If you are not able to read the entire dataset back from MongoDB because it’s too big, just query a manageable subset of it.
David